Sets
The Set interface is the base interface for collections which allows to store unique items, no necessary in any particular order.
Table of contents
- Create Sets
- HashSet
- LinkedHashSet
- TreeSet
- Can we store
nulls? - Which set to use?
- Set values MUST BE immutable
- Double brace initialization
- Mutable and immutable sets
Create Sets
Java 9 added static methods to the Set interface, Set.of(), that simplifies the creation of sets.
package demo;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> a = Set.of( "a", "b", "c" );
System.out.printf( "Set %s%n", a );
}
}
The above will simply print the set’s elements, in no particular order.
Set [a, b, c]
Sets can only contain unique elements. The Set.of() method will throw an IllegalArgumentException if duplicate elements are provided. Consider the following example.
IllegalArgumentException!! package demo;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
/* ⚠️ Throws IllegalArgumentException!! */
final Set<String> a = Set.of( "a", "a", "a" );
System.out.printf( "Set %s%n", a );
}
}
The above example will fail as expected.
Exception in thread "main" java.lang.IllegalArgumentException: duplicate element: a
at java.base/java.util.ImmutableCollections$SetN.<init>(ImmutableCollections.java:712)
at java.base/java.util.Set.of(Set.java:503)
at demo.App.main(App.java:8)
Generally, sets do not fail when duplicates are added. Instead duplicate elements are simply ignored. This is a unique behaviour of the Set.of() methods.
HashSet
HashSet is an implementation of the Set interface based on hash functions and buckets, as shown in the following diagram.
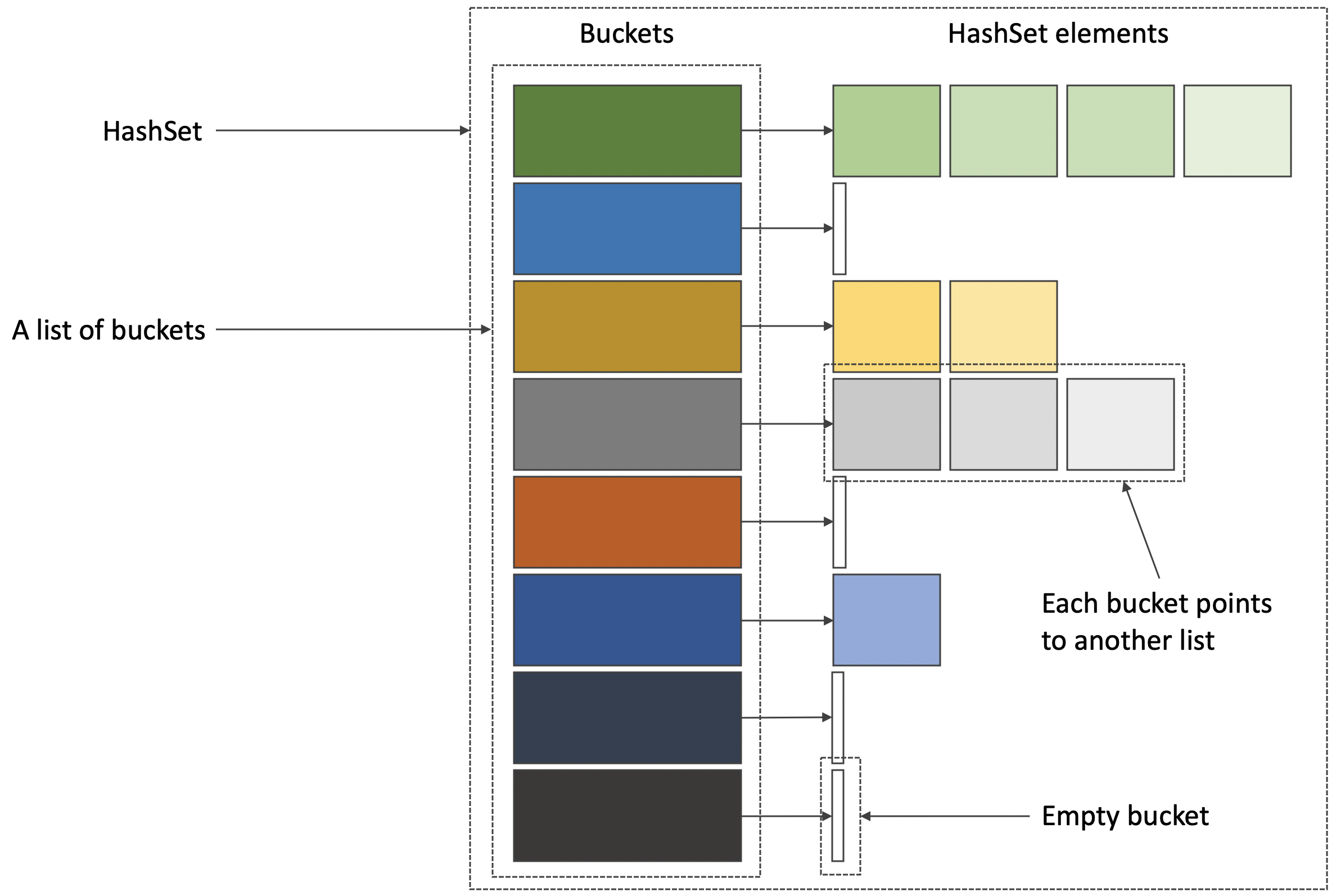
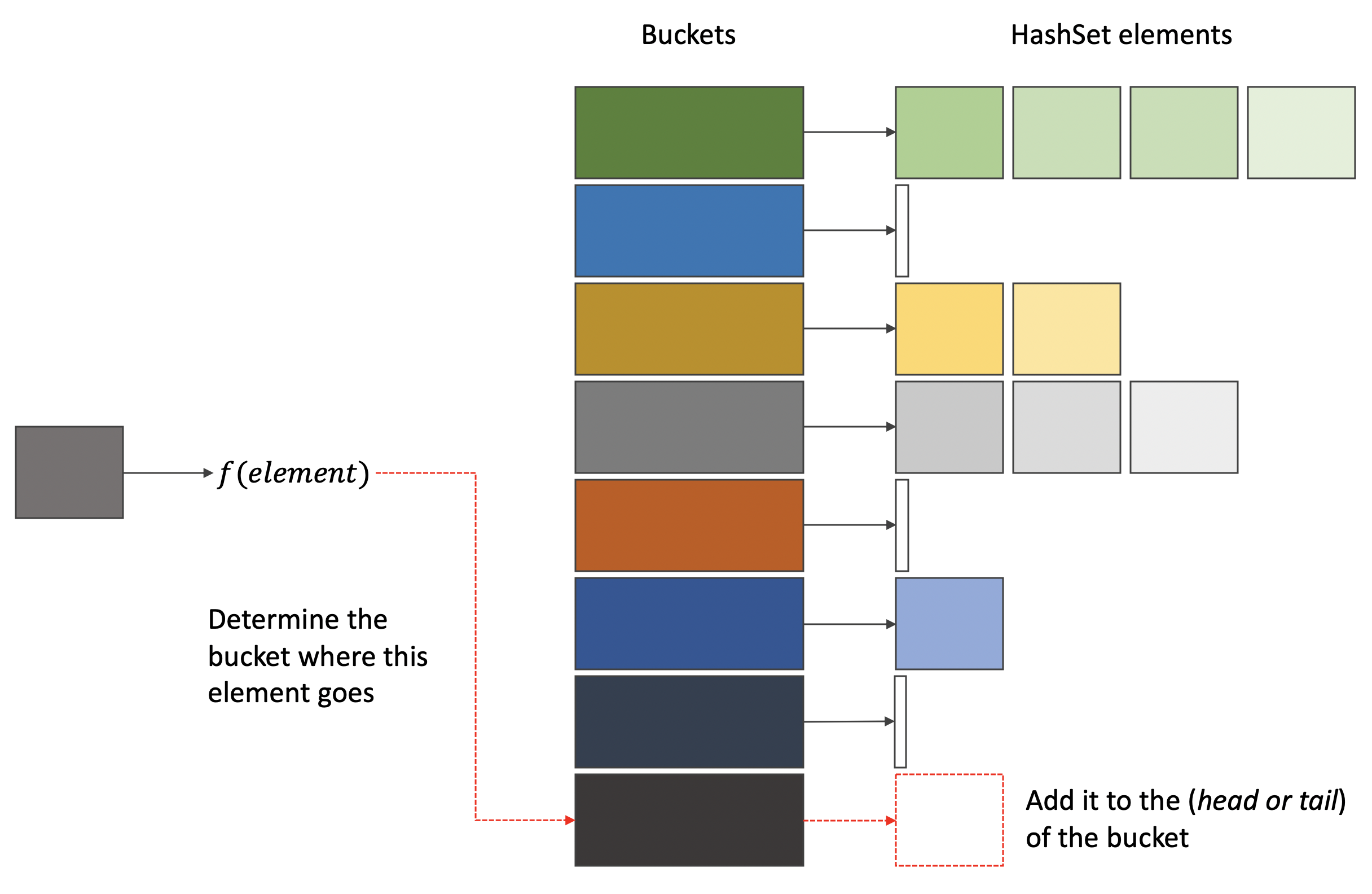
A HashSet can be seen as a list of lists, where elements are placed in the bucket they belong. A hash function is used to determine the bucket the elements belongs to, as shown in the following diagram.
The HashSet will use the element’s hashCode() method to determine the bucket to which the element belongs, then the equals() method to determine whether this already exists within the bucket, as shown in the following diagram.
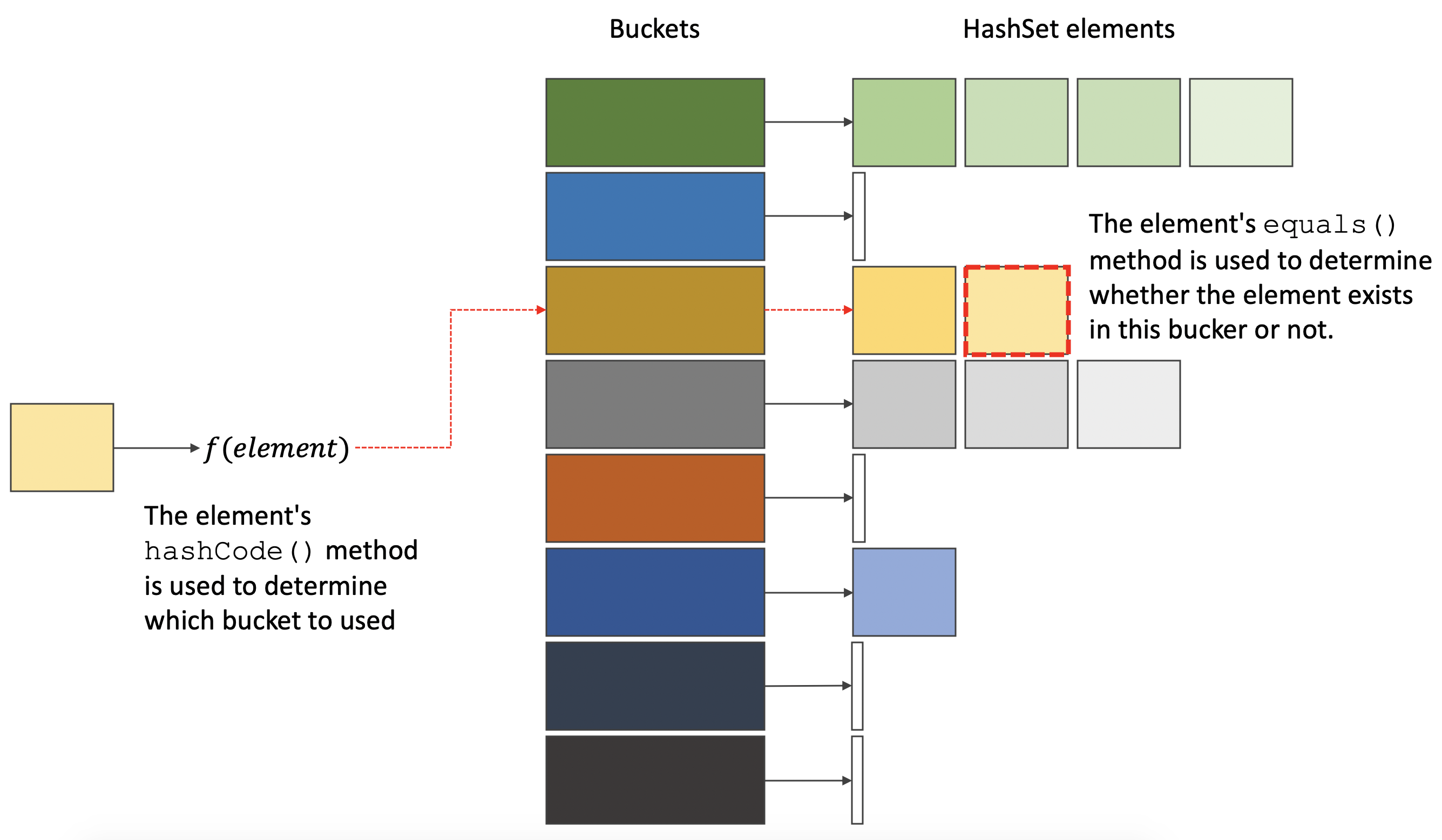
The relation between these two methods is so strong that the Effective Java book has an item about this, Item 11: Always override hashCode when you override equals.
A HashSet can be created like any other object, as shown next.
package demo;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new HashSet<>();
a.add( "b" );
a.add( "c" );
a.add( "a" );
System.out.printf( "Set %s%n", a );
}
}
The above example creates a set and adds three elements to the set. We can provide hits to the HashSet constructor about its initial capacity and the load factor. The load factor is the relation between number of buckets and the size of the set. This is a trade-off between memory used and performance. In most cases the default load factor value works well, but there are cases where this needs to be tuned.
It is always recommended to provide an initial capacity when this is known as it minimises the number of times the HashSet has to resize its internal data structures, as shown in the following example.
package demo;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new HashSet<>( 3 );
a.add( "b" );
a.add( "c" );
a.add( "a" );
System.out.printf( "Set %s%n", a );
}
}
Both examples will print the same output.
Set [a, b, c]
The HashSet’s add() method returns a boolean indicating whether the element that was offered was added or not. When adding an element that already exists in the set, the add() method returns false, as shown in the following example.
package demo;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new HashSet<>();
a.add( "b" );
a.add( "c" );
a.add( "a" );
/* Add an element that already exists */
final boolean wasAdded = a.add( "a" );
System.out.printf( "Was duplicate added? %s%n", wasAdded ? "YES" : "NO" );
System.out.printf( "Set %s%n", a );
}
}
The add() method is defined by the Collection interface and all collections, sets included, must honour the contracts defined by the Collection interface.
The duplicate element is not added to the set as also indicated in the following output.
Was duplicate added? NO
Set [a, b, c]
In the above examples, the output is always returned in alphabetical order. This may give the wrong impression that the HashSet always returns the elements in a given order. The order in which the elements are returned is not guaranteed and may vary between different versions of the JVM and JRE. There are other set implementations, such as LinkedHashSet and TreeSet, that always return the elements in a specific order.
LinkedHashSet
LinkedHashSet is a HashSet that also preserve the order in which items are returned. Consider the following example.
package demo;
import java.util.LinkedHashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new LinkedHashSet<>( 3 );
a.add( "b" );
a.add( "c" );
a.add( "a" );
System.out.printf( "Set %s%n", a );
}
}
The above program will always return the element in the same order these where added.
Set [b, c, a]
LinkedHashSet uses a doubly linked list to preserve the order in which the elements are added to the set.
TreeSet
TreeSet is another set implementation that uses a tree data structure. The TreeSet is based on the red–black self-balancing binary search tree implementation.
 (
(The tree marks its nodes red or black, hence the name, and rebalances itself following an addition or deletion of elements, guaranteeing searches in O(log n) time. This makes mutation more complex as the tree needs to be rebalanced every time elements are added or removed.
TreeSet does not outperform the HashSet when searching elements. In most case the `HashSet` finds elements faster than the TreeSet.Consider the following example.
package demo;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new TreeSet<>();
a.add( "b" );
a.add( "c" );
a.add( "a" );
System.out.printf( "Set %s%n", a );
}
}
In the above example, the TreeSet stores the given strings in alphabetical order. We can control how elements are handled by the TreeSet by providing a Comparator instance, as shown next.
package demo;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new TreeSet<>( Comparator.reverseOrder() );
a.add( "b" );
a.add( "c" );
a.add( "a" );
System.out.printf( "Set %s%n", a );
}
}
Different from the previous example, the set will return the elements in reverse order, as shown next.
Set [c, b, a]
The order in which the elements are sorted is governed by the provided Comparator or by their natural ordering (the element implements Comparable).
Note that adding elements to a TreeSet which do not support natural ordering (elements do not implement Comparable) and without providing a Comparator will throw a ClassCastException at runtime.
ClassCastException!! package demo;
import java.awt.Point;
import java.util.Set;
import java.util.TreeSet;
public class App {
public static void main( final String[] args ) {
final Set<Point> a = new TreeSet<>();
/* ⚠️ Throws ClassCastException!! */
a.add( new Point( 1, 2 ) );
System.out.printf( "Points %s%n", a );
}
}
The Point class does not implement the Comparable interface, thus this type of object does not provide natural ordering. A Comparator needs to be provided to the TreeSet to be able to work with the Point class, as shown in the following example.
package demo;
import java.awt.Point;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class App {
public static void main( final String[] args ) {
/* Compare by point x then point y */
final Comparator<Point> comparator =
Comparator.comparing( Point::getX ).thenComparing( Point::getY );
final Set<Point> a = new TreeSet<>( comparator );
a.add( new Point( 1, 2 ) );
System.out.printf( "Points %s%n", a );
}
}
We can store any object to the TreeSet as long as we provide a Comparator when the elements being stored do not implement Comparable. The above will print.
Points [java.awt.Point[x=1,y=2]]
The TreeSet always store the elements sorted.
Can we store nulls?
Some set implementations accept nulls while others not, as shown in the following table.
| Set | Allows nulls |
|---|---|
HashSet | YES |
LinkedHashSet | YES |
TreeSet | NO |
Following is a basic example that tries to add a null for each of the above implementations
HashSet(acceptsnulls)package demo; import java.util.HashSet; import java.util.Set; public class App { public static void main( final String[] args ) { final Set<String> names = new HashSet<>(); names.add( null ); System.out.printf( "Names %s%n", names ); } }HashSetacceptsnulls. At most, there can be only onenullin a set.LinkedHashSet(acceptsnulls)package demo; import java.util.LinkedHashSet; import java.util.Set; public class App { public static void main( final String[] args ) { final Set<String> names = new LinkedHashSet<>(); names.add( null ); System.out.printf( "Names %s%n", names ); } }LinkedHashSetacceptsnulls. At most, there can be only onenullin a set.TreeSet(does not acceptnulls)⚠ The following example will compile but will throwNullPointerException!!package demo; import java.util.Set; import java.util.TreeSet; public class App { public static void main( final String[] args ) { final Set<String> names = new TreeSet<>(); /* ⚠️ Throws NullPointerException!! */ names.add( null ); System.out.printf( "Names %s%n", names ); } }TreeSetdoes not work withnulls and aNullPointerExceptionwill be thrown if we attempt to addnulls.Exception in thread "main" java.lang.NullPointerException at java.base/java.util.TreeMap.compare(TreeMap.java:1291) at java.base/java.util.TreeMap.put(TreeMap.java:536) at java.base/java.util.TreeSet.add(TreeSet.java:255) at demo.App.main(App.java:11)
Which set to use?
HashSet is my first choice as it is very fast. With that said, HashSet consumes more space when compared to TreeSet. LinkedHashSet is a variant of HashSet, where the elements’ order is preserved, at some extra space cost. The following table shows which set I prefer and a one sentence describing the motivation behind this decision.
| Set | Motivation |
|---|---|
HashSet | My default go-to set implementation |
LinkedHashSet | When I need to preserve the insertion order of the elements |
TreeSet | When ordering is important and no need to deal with nulls |
Each set implementation is compared in more details next.
Performance
HashSetperforms faster thanTreeSet. This comes to a surprise especially when searching element.Ordering
HashSetprovides no ordering guarantees.LinkedHashSetpreserves the order in which the elements are added whileTreeSetalways contains the elements in an ordered manner (based on the elements natural ordering or the providedComparator).When an ordered set (a set of type
SortedSet) is required, it is recommended to create aHashSetand populate it with the elements first. Then create anTreeSetfrom theHashSet, as shown next.package demo; import java.util.HashSet; import java.util.Set; import java.util.SortedSet; import java.util.TreeSet; public class App { public static void main( final String[] args ) { final Set<String> temporary = new HashSet<>(); temporary.add( "Jade" ); temporary.add( "Aden" ); final SortedSet<String> ordered = new TreeSet<>( temporary ); System.out.printf( "Ordered: %s%n", ordered ); } }This example takes advantage from the bulk population of the
TreeSetand does not suffer the cost associated with the rebalancing with every element addition.nullsupportTreeSetdoes not supportnulls.HashSetandLinkedHashSetsupportnulls.ⓘ NoteThere can be at most onenullin a set.Comparison
The
HashSetandLinkedHashSetuse the element’shashCode()method to determine which bucket to use and theequals()method to compare between elements within the same bucket.The
TreeSetrelies on thecompareTo()method for same purpose.The relation between the collections and the elements which they contain is discussed in more depth in the relation to objects section.
Set values MUST BE immutable
Modifying the elements after adding them to the set may break the set. Consider the following example.
package demo;
import java.awt.Point;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Point point = new Point( 1, 1 );
final Set<Point> points = new HashSet<>();
points.add( point );
System.out.println( "-- Before modifying the element ----" );
System.out.printf( "Is point %s in set? %s%n", point, points.contains( point ) );
/* Modify the point */
point.y = 10;
System.out.println( "-- After modifying the element -----" );
System.out.printf( "Is point %s in set? %s%n", point, points.contains( point ) );
System.out.printf( "Elements in set: %s%n", points );
}
}
In the above example, a point is added to the set and then modified. After the point is modified, the set is not able to find the same point (the same object reference) and will print the following.
-- Before modifying the element ----
Is point java.awt.Point[x=1,y=1] in set? true
-- After modifying the element -----
Is point java.awt.Point[x=1,y=10] in set? false
Elements in set: [java.awt.Point[x=1,y=10]]
The strangest thing when debugging such problems is that the set seems to contain this element, as printed in the last line from the above output. The issue here happened because the element now belongs to a different bucket and that’s why the set is not able to find it.
How can we modify elements that are contained within a set?
If an element within a set is mutable and needs to be updated, then it should first be removed from the set, updated and then added back to the set, as shown in the following example.
package demo;
import java.awt.Point;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Point point = new Point( 1, 1 );
final Set<Point> points = new HashSet<>();
points.add( point );
/* Remove, update and add */
points.remove( point );
point.y = 10;
points.add( point );
System.out.printf( "Is point %s in set? %s%n", point, points.contains( point ) );
}
}
The order in which these three operations happen is quite important as if we update the element before removing it, the remove may not remove the element and then end up with two instances of the same object in the same set.
Double brace initialization
Consider the following example.
package demo;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> a = new HashSet<>() { {
add( "a" );
add( "b" );
add( "c" );
} };
System.out.printf( "Set %s%n", a );
}
}
The above example makes use of double brace initialization. An inner anonymous class is created and the init block is used to add the elements to the set. The above example is similar to the following.
package demo;
import java.util.HashSet;
public class MyStringSet extends HashSet<String> {
/* Initialisation block */
{
add( "a" );
add( "b" );
add( "c" );
}
}
I’ve never used this pattern and prefer other constructs instead, such as Set.of(), Guava Sets.newHashSet() method. I’ve added this example here as you may encounter this in code.
Mutable and immutable sets
Immutable (also referred to as unmodifiable) sets cannot be modified, while mutable (also referred to as modifiable) sets can be modified. Consider the following example.
UnsupportedOperationException!! package demo;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> modifiable = new HashSet<>( 3 );
modifiable.add( "a" );
modifiable.add( "b" );
modifiable.add( "c" );
final Set<String> unmodifiable = Collections.unmodifiableSet( modifiable );
/* ⚠️ Throws UnsupportedOperationException!! */
unmodifiable.add( "d" );
}
}
Changing the unmodifiable set will throw an UnsupportedOperationException.
Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.Collections$UnmodifiableCollection.add(Collections.java:1062)
at demo.App.main(App.java:17)
Changes to the underlying set will also affect the immutable set
package demo;
import java.util.Collections;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<String> modifiable = new HashSet<>( 3 );
modifiable.add( "a" );
modifiable.add( "b" );
modifiable.add( "c" );
final Set<String> unmodifiable = Collections.unmodifiableSet( modifiable );
/* The immutable set will be modified too */
modifiable.add( "d" );
System.out.printf( "Set: %s%n", unmodifiable );
}
}
The unmodifiable set uses the given set as its underlying data structure. Therefore, any changes to the underlying data structure will affect the unmodifiable set too, as shown next.
Set: [a, b, c, d]
Consider the following class.
package demo;
import java.util.Collections;
import java.util.Set;
public class Data {
private final Set<Integer> sample;
public Data( final Set<Integer> sample ) {
this.sample = Collections.unmodifiableSet( sample );
}
public Set<Integer> getSample() {
return sample;
}
@Override
public String toString() {
return String.format( "Data: %s", sample );
}
}
The Data class contains an unmodifiable set, named sample. We cannot add or remove data to/from the sample set. Consider the following example.
UnsupportedOperationException!! package demo;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<Integer> source = new HashSet<>( 3 );
source.add( 7 );
source.add( 4 );
source.add( 11 );
final Data data = new Data( source );
/* ⚠️ Throws UnsupportedOperationException!! */
data.getSample().add( 6 );
}
}
The above example compiles and fails whenever we try to modify the sample set through the enclosing Data class.
Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.Collections$UnmodifiableCollection.add(Collections.java:1062)
at demo.App.main(App.java:16)
The above example may give you the wrong impression that the sample set is immutable. Consider the following example.
package demo;
import java.util.HashSet;
import java.util.Set;
public class App {
public static void main( final String[] args ) {
final Set<Integer> source = new HashSet<>( 3 );
source.add( 7 );
source.add( 4 );
source.add( 11 );
final Data data = new Data( source );
/* Modify the source */
source.add( 6 );
/* The data is changed too as a side effect */
System.out.println( data );
}
}
The above example is modifying the set through the source variable, which happens to be the underlying data structured of the immutable set, sample. We are still able to modify the sample by modifying the underlying set.
Data: [11, 4, 6, 7]
Defensive copying is a technique which mitigates the negative effects caused by unintentional (or intentional) modifications of shared objects. Instead of sharing the reference to the original set, we create a new set and use the reference to the newly created copy instead. Thus, any modification made to the source will not affect our set.
To address this problem, we need to change the following line
this.sample = Collections.unmodifiableSet( sample );
with (if you are working with Java 9 or above)
this.sample = Set.copyOf( sample );
or (if you are working with Java 8 or you need to handle nulls)
this.sample = Collections.unmodifiableSet( new HashSet<>( sample ) );
There are at least two ways to solve this problem, both options will achieve the same thing.
package demo;
import java.util.Set;
public class Data {
private final Set<Integer> sample;
public Data( final Set<Integer> sample ) {
/**/this.sample = Set.copyOf( sample );
}
public Set<Integer> getSample() {
return sample;
}
@Override
public String toString() {
return String.format( "Data: %s", sample );
}
}
Any changes made to the source set, will not affect our set. The above example is truly immutable.